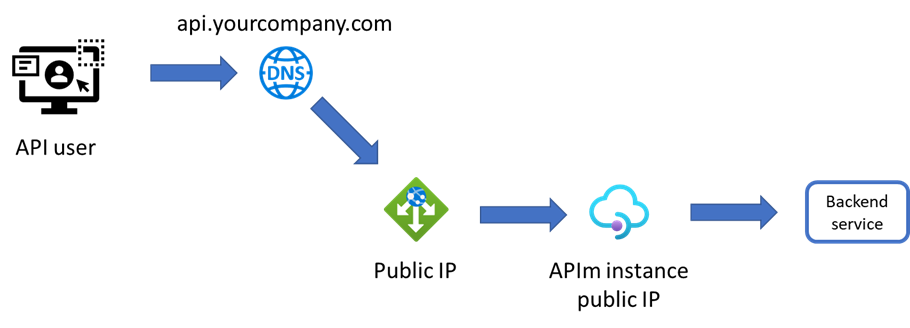
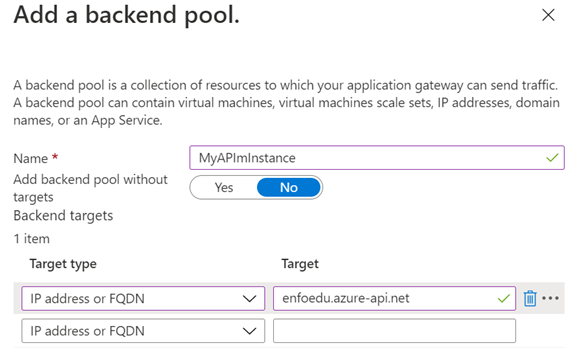
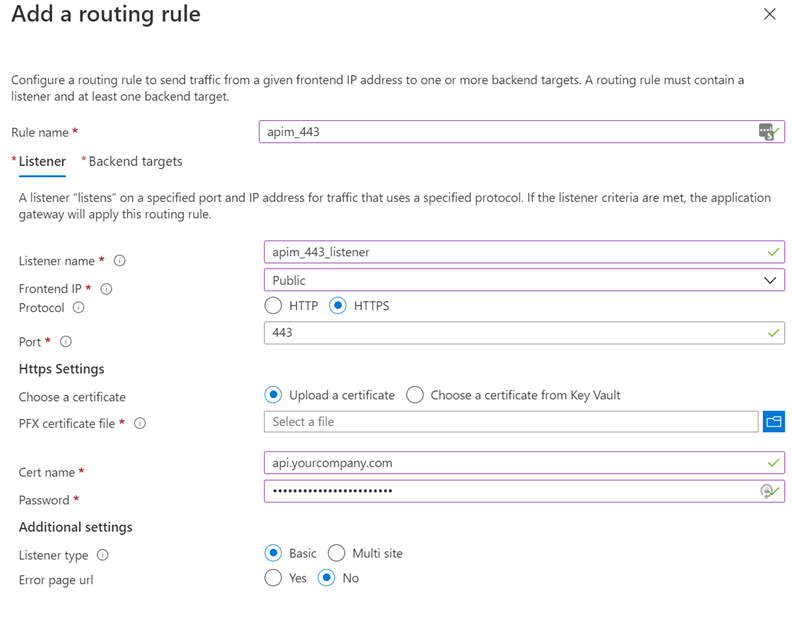
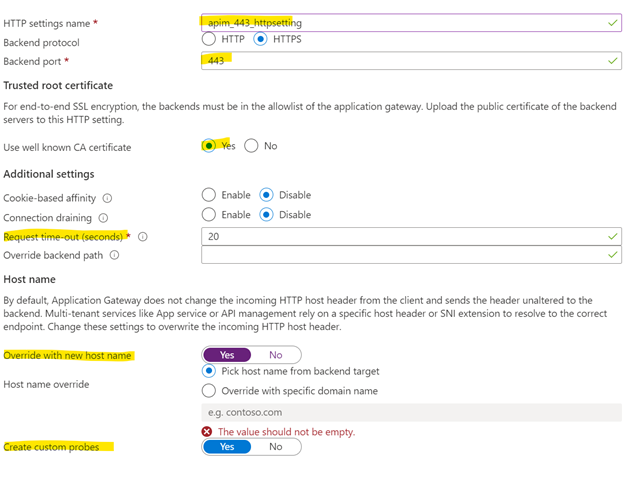
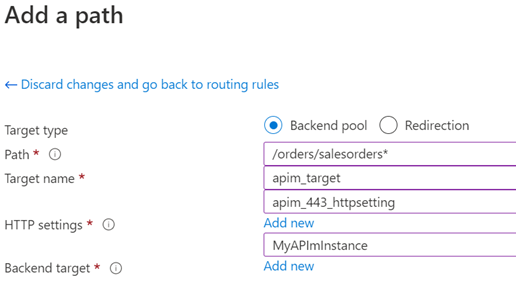
This is the sequel to my previous post Using AppGw in front of APIm, in which I showed how to setup an Application Gateway (AppGw) in-front of an APIm instance.
In this post I will show how you should (could) configure a health probe, configure the firewall and lastly how to secure your APIm to only accept calls that has been routed thru your AppGw.
Configuring a health probe
Why do you need this? A health probe is used by the AppGw to see which services in a backend pool is healthy. If you do not have more than one instance in a backend pool, perhaps you do not need this feature. If you have multiple instances, the AppGw will only send requests to the healthy instances. This is basic load balancing.
To configure a healthprobe for APIm you can use the “status” service that is available in all APIm instances. You can test it by sending a GET to https://{yourAPIminstanceFQDN}/status-0123456789abcdef. If you receive 200 Service Operational, then you know the service is healthy.
We can use this call to get the APIm status in our health probe.
Setting it up
Start by clicking “Health probes” in the left menu.

The find and click + Add at the top of the new blade.
Set the values for the health probe like this:
- Name: The name of the probe.
- Protocol: HTTPs (you do not use HTTP)
- Host: The FQDN of your APIm instance, usually servicename.azure-api.net.
- Pick hostname from the HTTP settings: I use NO, you could use YES if you know what you are doing.
- Pick port from the HTTP settings: I use YES, because I know that the port is set there.
- Path: Set to /status-0123456789abcdef
Leave the rest as is but make sure you select your HTTP setting you created in the previous post.
End the configuration by testing it. Click Test.
It tests the setting:

And hopefully, it works.

The firewall
This is so easy; it might not even need to be documented.
If you configured the firewall according to the steps in part one, you are already protected but I will go thru the different settings and provide some experience.
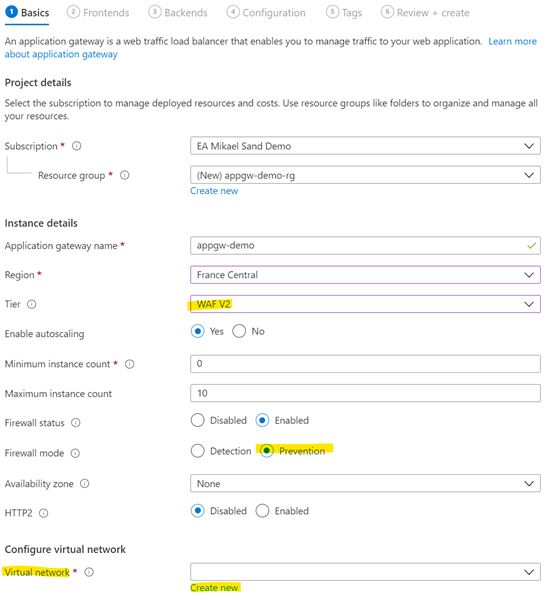
This is the basic configuration:

Basic stuff
Tier should be set to WAF V2. The standard is cheaper but does not contain the WAF.
Firewall status: should be enabled but you could disable it in DEV to know if a caller is locked out because of the firewall or not.
Firewall mode: should be set to Prevention. You do want to keep the bad people out, to prevent them. The other setting will just log a bad person.
Exclusions
This is where you configure the WAF to not block calls based on “strange data”. The firewall scans the incoming request for “strange data” or junk-data if you will. A long string of letters, such as an auth-header of a cookie can be considered strange, and the firewall will reject it. You might, therefore, exclude some settings.
The official documentation gives some examples. I always add: Request Header Name, Starts with, Auth to eliminate any authorization issues.
Global parameters
Note that these settings are global. All incoming calls will be scanned using these settings.
Inspect request body: If you turn this on the WAF will automatically scan incoming requests for strange data. For instance, if the incoming request is marked as Content-Type: application/json, the WAF will validate the JSON and reject it if the JSON is malformatted.
Max request body size: Here is a big limitation of the WAF. If you turn on inspection, you cannot accept calls bigger than 128 kb. I recently had a project where the caller wanted to send files in excess of 20 mb as request bodies. We had to device a workaround to keep the WAF inspection turned on for everything else. The settings are global.
File upload limit: If you can get your caller to send the messages as file uploads instead of request bodies, the upper limit is 100 mb.
Rules
Click the Rules tab at the top of the blade.

The basic setting is to use the max version of OWASP to be protected from the bad people. For more information on OWASP visit their website.
You can leave the Advanced rule configuration as disabled for now. This feature is useful if your callers are expressing issues and you need to disable a certain rule to allow the calls. Just find the affected rule and uncheck it.

Please be aware that: these settings are global and limits your security baseline. Try to update the caller instead.
Secure your APIm
The WAF has its own IP address, and you can use that for IP-whitelisting. You can also have the AppGw set a custom header and have APIm look for that header. This method will not be used here but look under “Rewrites” in the left menu.
Find the IP address
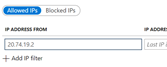
To find the IP address of your AppGw, look under Overview and to the right you will find the Frontend Public IP address:

In my case it is 20.74.19.2.
Update APIm global policy
Switch to your APIm instance and select APIs in the left menu. Then select All APIs (this is the global policy). Lastly select Add Policy under Inbound processing.
Choose Filter IP addresses and in the new page, choose Add IP filter.
Since we will not be using a range of IP addresses, just fill in the first box with the IP address of your AppGw.
This will only allow calls from that IP address. The policy file will look like this:
<inbound>
<ip-filter action=”allow”>
<address>20.74.19.2</address>
</ip-filter>
</inbound>
If someone calls your APIm directly they will get an error message. Here is an example:

Conclusions
There are other useful features for you to explore. For instance, you can hook up the AppGw to a Log Analytics instance and look at the data being logged. This is very useful if your callers report errors due to rules or message inspection. You can also use it to show that the firewall stops incoming malicious calls.
I have found this service a useful and welcome addition to APIm in Azure, and I encourage you to try it out in your API platform.