There are a lot of solutions to this particular question. The need is that we only poll data from a database on Sundays.
This might be solved using a stored procedure that only returns data on Sundays. It might also be solved by using the famous schedule task adapter to schedule the poll for Sundays. You can also do some cool coding thing using a custom pipeline component that rejects data on all other days but Sundays. Your scenario might be very well suited for one of these solutions, the scenario presented by my colleague Henrik Wallenberg did not fit any of those.
The scenario
A database is continuously updated thru out the week but we need the export data from a specific table every Sunday at 6pm. We cannot use the schedule task adapter nor stored procedures. We decided to try to trick BizTalk using the PolledDataAvailableStatement in the WCF-SQL adapter on a receive port. Turns out it works! Here is how.
Please note that this does not work if you cannot use ambient transactions.
According to this post, you must set Use Ambient Transaction = true if you need to us a polledDataAvailableStatement. This seems really odd to me but after receiving feedback about this article I know that it is true.
The solution
- Create the receive location and polling statement.
- Find the setting PolledDataAvailableStatement
- Set it to:
SELECT CASE WHEN DATEPART(DW, GETDATE()) = 1 THEN 1 ELSE 0 END - Set the polling interval to
3600(once an hour).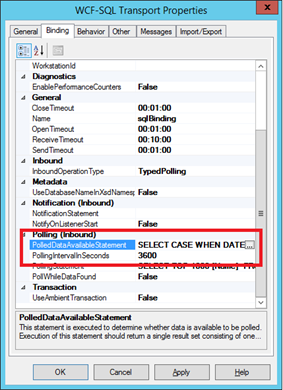
- Apply your settings.
- Set the Service Window to only enable the receive location between 6pm and 6:30 pm.
- Now the receive location will only poll once a day and only execute the polling statement on Sundays.
More information
How does this work? It is very simple really. The property PolledDataAvailableStatement (more info here) needs to return a resultset (aka a SELECT). The top leftmost, first if you will, cell of this resultset must be a number. If a positive number is returned, then the pollingstatement will be executed, otherwise not.
The SQL statement uses a SQL built-in function called DATEPART with a parameter value of “dw”, which returns “Day Of Week”. More information here.
Day 1 is by default in SQL Server a Sunday, because Americans treat days and dates in a very awkward way. There might be some tweaking to your statement in order to make Sunday the 7th day of the week. So the statement SELECT CASE WHEN DATEPART(DW, GETDATE()) = 1 THEN '1' ELSE '0' END returns a 1 if it is day 1 (Sunday). This means that the pollingstatement will only be executed of Sundays.
We then set the pollinginterval to only execute once an hour. This, together with the service window, will make sure the statement only executes once a day (at 6pm) as the receive location is not enabled the next hour (7pm). You could update the SQL statement to take the hour of the day into consideration as well but I think it is better to not even execute the statement.
The downside
This is not a very reliable solution though. What if the database was unavailable that one time during the week when data is transported? Then you have to either wait for next week or manually update the PolledDataAvailableStatement to return a 1, make sure the data is transported and then reset the PolledDataAvailableStatement again.
In conclusion
It is a very particular scenario in which this solution is viable and even then it needs to be checked every week. Perhaps you should consider another solution. Thanks to Henrik for making my idea a reality and testing it out. If you want to test it out for yourself, some resources to help you can be found here: InstallApp Script